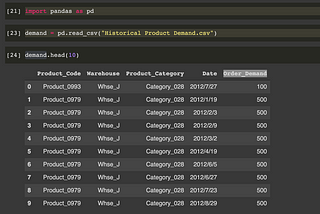
Duy Anh NguyenPandas Fluency — Introducing Pandas (P1)Pandas is a popular library for data analysis built on top of the Python programming language. Pandas can be though as a digital toolbox…May 7, 2021May 7, 2021
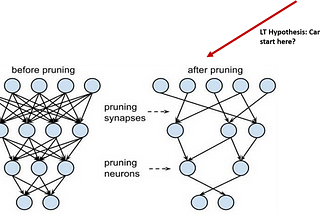
Duy Anh Nguyenloop#1 Hyper-parameters, The Lottery Ticket Hypothesis, and Weight&Biases platformML Concept: What are Hyper-parameters?Sep 5, 2020Sep 5, 2020
Duy Anh NguyenDeep Reinforcement Learning part 1 — Hello World !!!!IntroductionJul 2, 2020Jul 2, 2020
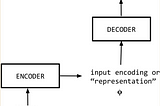
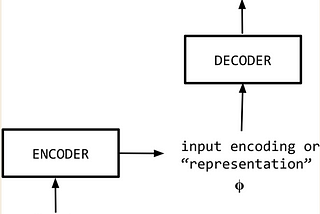
Duy Anh NguyenNLP Fundamentals — Sequence Modeling (P7)Sequence-to-sequence (S2S) models are a special case of a general family of models called encoder–decoder models. An encoder–decoder model…Mar 6, 2020Mar 6, 2020
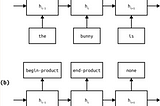
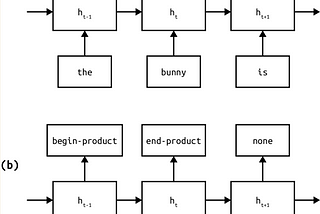
Duy Anh NguyenNLP Fundamentals — Sequence Modeling (P6)Sequence prediction tasks require us to label each item of a sequence. Such tasks are common in natural language processing. Some examples…Mar 5, 2020Mar 5, 2020
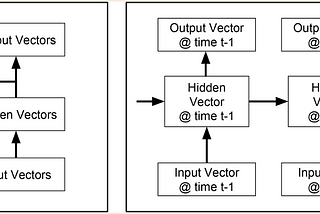
Duy Anh NguyenNLP Fundamentals — Sequence Modeling (P5)A sequence is an ordered collection of items. Traditional machine learning assumes data points to be independently and identically…Mar 5, 2020Mar 5, 2020
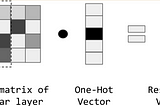
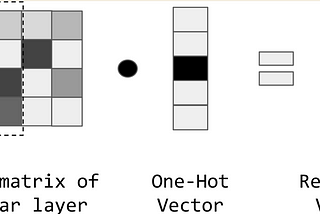
Duy Anh NguyenNLP Fundamentals — Embedding Words(P4)Representing discrete types (e.g., words) as dense vectors is at the core of deep learning’s successes in NLP. The terms “representation…Mar 5, 2020Mar 5, 2020
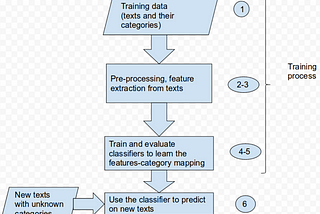
Duy Anh NguyenNLP Fundamentals — Text Classifier(P3)In this section we discussed feature engineering techniques using neural networks, such as word-embeddings, character-embeddings. The…Mar 4, 2020Mar 4, 2020
Duy Anh NguyenNLP Fundamentals — Text Classifier(P2)“Organizing is what you do before you do something, so that when you do it, it is not all mixed up”Mar 3, 2020Mar 3, 2020